이전에 라우팅을 간략하게 요약하면서 설명했지만 다른 라우팅 프로토콜들을 다루기 전에 라우팅의 기본적인 요소와 내용들을 조금 더 상세하게 다루도록 하겠습니다.
1. AS (Autonomous System)
동일한 라우팅 정책으로 하나의 관리자에 의해 운영되는 네트워크를 말합니다. 각 시스템을 구분하기 위해 IANA에서 16비트 크기의 고유한 AS 번호를 부여하며 이를 망식별번호 라고 부릅니다.

네트워크의 규모가 커질수록 라우팅 정보의 양 역시 많아지고, 이 많은 라우팅 정보를 하나의 프로토콜로 관리하는것은 불가능합니다. 관리를 효율적으로 하기 위해서 네트워크 관리 범위를 나누고, 식별을 위해 번호를 부여하는 것입니다.
이렇게 내부와 외부를 구분짓게 되면서 몇가지 이점이 생깁니다.
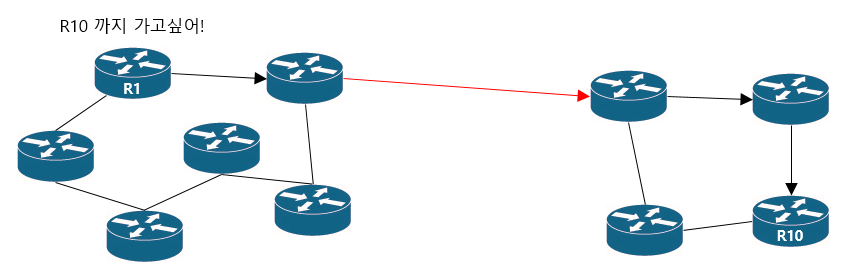
기존에는 R1 과 R10이 통신하려면 중간에 낀 노드들의 라우팅 정보를 모두 알아야만 했다면, AS를 구분짓게 되면서 모두 알 필요가 없어지는겁니다.
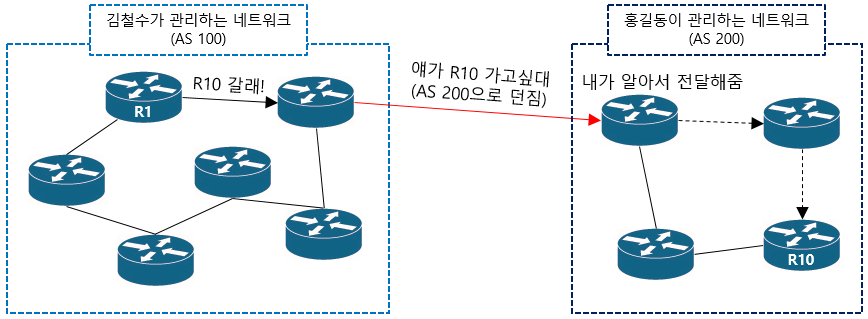
그러면 각 네트워크들은 AS로 항하는 라우팅 정보만 알아도 충분하니 내부에서는 알아서 라우팅해줄수 있으며 이런 방식을 사용하면 보안이 강화되는 효과까지 생깁니다.
집에서 배달 음식을 시켰는데, 배달기사가 집 문을 열고 들어와서 내가 있는 방(내부 네트워크)까지 음식을 가져다 놓는다면 굉장히 불편할겁니다. 그래서 음식은 문앞에 두고 가되, 동생이 음식을 갖고 들어와서 내방에 가져다 주는겁니다.
이러면 배달 기사는 집 구조가 어떻게 생겼는지, 작은방에서 안방으로 이동했는지 등의 세세한 정보를 알 필요가 없어지고 집 구조를 잘 아는 가족이 안전하게 음식을 배달해 주니 나도 좋은거죠.
2. IGP, EGP
IGP(Interior Gateway Protocol)는 AS 내부의 라우팅방식이고 EGP(Exterior Gateway Protocol)는 다른 AS와 사용하는 라우팅입니다. 느낌적으로는 IGP는 집내부의 현관문, 안방문 등을 어떻게 거쳐서 갈 것인가? 를 정하는것이고 EGP는 일상적으로 사용되는 네비게이션의 경로찾기 기능과 같겠습니다.
| 구분 | IGP | EGP |
| Neighbor 결정 | 자동탐색 | 수동설정 |
| Convergence | 빠름 | 안정성 위주 둔감 |
| 라우팅 범위 | AS 내부 라우터 | AS 상호간 |
가족이 배달해주는 음식은 믿을 수 있겠죠. IGP는 AS 내부의 라우팅을 수행하기 때문에 라우팅 신뢰성이 높습니다.
배달기사는 외부인이니 안전하지 않을 수도 있고 신뢰성이 떨어집니다. 마찬가지로 EGP는 다른 AS와 라우팅을 수행하므로 신뢰성이 낮고 빠른 수행보다는 보안과 제어에 목적을 두고 있습니다.
3. 메트릭 (Metric), AD (Administrative Distance)
동적 라우팅 프로토콜들이 최적의 경로를 선택하는 기준을 메트릭이라고 합니다. 프로토콜마다 메트릭이 다르기 때문에 각 프로토콜별 특성을 정확하게 파악하고 있어야 할 필요가 있습니다. 이후 각 프로토콜을 다루면서 상세하게 설명하기 때문에 간략하게 적었습니다.
- RIP : 목적지까지 거치는 라우터의 수(Hop Count)
- EIGRP : 대역폭, 지연, 신뢰도, 부하, MTU 등을 특정 공식에 대입한 결과값 사용
- OSPF : 대역폭, 속도에 기초한 Link Cost
- IS-IS : Hop Count와 유사한 개념을 이용한 Cost
- BGP : 속성(Attribute) - Next Hop, AS_path, MED, Weight, Local Prefrence 등
하나의 네트워크에서 두 개 이상의 라우팅 프로토콜이 사용될 때는 프로토콜의 우선순위를 정하고 경로를 계산하기 위해 AD값이 낮은 프로토콜이 계산한 경로가 사용됩니다.
| Route Source | Default Distance |
| Direct Connect | 0 |
| Static Route | 1 |
| EIGRP Summary Route | 5 |
| External BGP | 20 |
| Internal EIGRP | 90 |
| IGRP | 100 |
| OSPF | 110 |
| IS-IS | 115 |
| RIP | 120 |
| EIGRP External Rotue | 170 |
| Internal BGP | 200 |
| Unknown | 255 |
4. Longest Match Rule
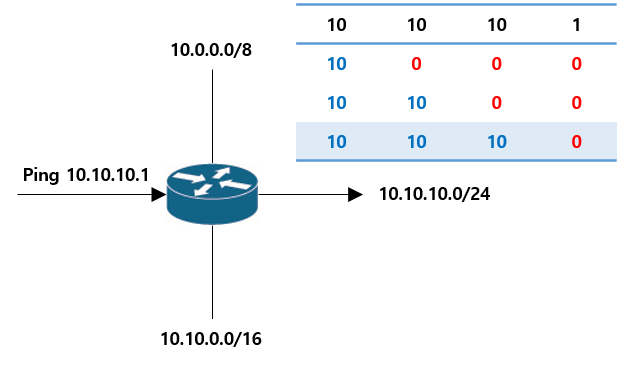
뭔가 영어가 길이서 부담스러운데 내용은 별거없습니다. 우리가 10.10.10.1로 ping을 보낸다고 생각해 보겠습니다.

만약 라우터가 예시와 같은 라우팅 테이블을 갖고 있을 때, 어디로 라우팅할지 확신이 없습니다. 이 상황에서 목적지와 라우팅 테이블이 가장 많이 일치하는 부분으로 라우팅한다는 것이 바로 Longest Match Rule입니다. 즉, 10.10.10.0/24 네트워크가 10.10.10.1 목적지와 가장 길게(많이) 매칭되니 라우팅될겁니다.
5. 최적의 경로결정
목적지로 가는 경로가 여러개일 경우에 Longest Matching Rule에 의해서 네트워크 주소가 가장 길게 일치하는 경로를 선택합니다.
같은 라우팅 프로토콜에서는 메트릭이 가장 낮은 경로를 우선으로 하고, 메트릭이 동일하다면 로드밸런싱됩니다.
다른 라우팅 프로토콜에서는 AD값이 가장 낮은 경로를 선택하여 라우팅됩니다.
6. 거리벡터 (Distance Vector Routing)
Bellman-Ford 알고리즘을 사용하여 최단거리를 구하고, 라우팅 정보를 전파함에 있어서 거리(Distance)와 방향(Vector)을 주기적으로 알려주는 방식입니다. 예시를 보겠습니다.
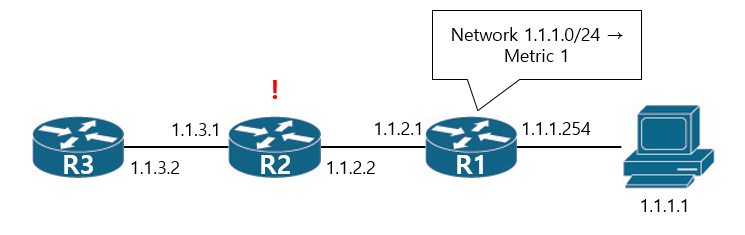
R1은 1.1.1.0/24 네트워크가 자신과 연결되어 있다는 사실을 인접한 라우터인 R2에게 전파합니다. 그러면 R2 역시 라우팅 테이블을 다음처럼 갱신할 수 있겠죠.

R1이 1.1.1.0/24 네트워크와 직접적으로 연결되어있으니, 자신은 1Hop 너머에 1.1.1.0/24 네트워크가 있다는 사실을 알게되었고 Metric에 이 사실을 반영합니다. 그리고 마찬가지로 자신과 인접한 R3 라우터에게 이 사실을 전파합니다.

R3 역시 1.1.1.0/24 네트워크가 2Hop 너머에 있다는 사실과 방향까지 알게 되었고 자신의 Metric에 반영합니다. 이런 방식으로 모든 라우터가 목적지 네트워크에 대한 거리(Distance)와 방향(Vector)을 학습하는것을 거리벡터 라우팅 프로토콜이라고 하며 RIP, EIGRP, BGP와 같은 프로토콜들이 이러한 방식을 사용합니다.
7. 링크상태 (Link State Routing)
링크 상태 라우팅은 홉, 방향뿐만 아니라 네트워크가 접속된 라우터의 id, 인접한 라우터의 정보, 링크의 비용 등 많은 요소들을 전파하고 이 정보를 기반으로 라우터가 토폴로지 전체를 파악하고, Dijkstra 알고리즘을 사용하여 최단경로를 찾습니다. 알고리즘에 대한 내용은 다음 포스팅에서 정리할 예정입니다.
링크 상태 라우팅은 라우터끼리 전파하는 정보의 양이 많은만큼 동작이 복잡하고 관리하기도 어렵습니다. 라우터 역시 알고리즘 연산에 거리벡터 라우팅보다 더 많은 자원을 쏟아야하지만 그만큼 규모가 큰 네트워크에서 사용하기에 적합하고 네트워크 구성의 변화가 있을 경우에 수렴되는 시간이 빠르다는 장점을 가집니다.
거리 벡터 라우팅과 링크 상태 라우팅에서 라우터가 인지하는 네트워크는 아래 사진과 같은 차이점이 있습니다.

거리 벡터 라우팅에서 R1은 방향과 홉 정도를 인지하고, 링크 상태 라우팅에서 R1은 어떤 네트워크가 무슨 라우터와 연결되어 있는지, 경로 비용이 얼마인지 등 상세한 정보를 가지고 있으며 네트워크 구성 전체를 파악합니다.
또한 링크 상태 라우팅은 노드가 계층적 구조를 가질 수 있어 대규모 네트워크에서 사용하기 더 적합합니다. 영역을 분리함으로써 라우터가 가지는 링크 상태 데이터베이스의 양을 줄이고, 영역 내의 링크 상태 정보의 양을 제한할 수 있게 됩니다.

대표적으로 OSPF와 같은 링크 상태 라우팅 프로토콜들이 있습니다.
8. Distance Vector와 Link State의 차이점
- 거리 벡터 라우팅은 Bellman-Ford 알고리즘을 사용하고 링크 상태 라우팅은 Dijkstra 알고리즘을 사용합니다.
- 거리 벡터 라우팅은 이웃 관점에서 토폴로지 정보를 수신하는 반면 링크 상태 라우팅은 네트워크 토폴로지 전체에 대한 완전한 정보를 수신합니다.
- 거리 벡터 라우팅은 거리(홉)를 기반으로 최단경로를 계산하지만 링크 상태 라우팅은 최소 비용을 기준으로 경로를 계산합니다.
- 링크 상태 라우팅은 링크의 상태만 업데이트합니다. 거리 벡터 라우팅은 라우팅 테이블 전체를 업데이트 하기 때문에 수렴 속도가 느립니다.
- 거리 벡터 라우팅은 업데이트를 주기적으로 수행하지만 링크 상태 라우팅은 트리거 업데이트를 사용하여 변화가 즉각적으로 반영됩니다.
- CPU, 메모리 등 라우터 자원의 사용률은 링크 상태 라우팅이 더 높습니다.
- 거리 벡터 라우팅은 구현과 관리가 간단합니다. 링크 상태 라우팅은 구현과 관리가 복잡하여 숙련도가 높은 관리자를 필요로 합니다.
- 거리 벡터 라우팅은 벨만 포드 알고리즘의 루핑 문제가 발생될 수 있습니다. 링크 상태 라우팅은 안정적입니다.
- 링크 상태 라우팅은 계층적 구조를 가질 수 있습니다.
'네트워크, 보안' 카테고리의 다른 글
| 라우팅 - RIP (Routing Information Protocol) (0) | 2022.03.29 |
|---|---|
| 라우팅 알고리즘 - 벨만포드(Bellman-Ford), 다익스트라(Dijkstra) (0) | 2022.03.04 |
| 라우팅 - Inter-VLAN Routing (0) | 2022.02.17 |
| 라우팅 - 정적 라우팅 (Static Routing) (2) | 2022.02.03 |
| 네트워크 - 이더채널 (EtherChannel) (0) | 2022.01.24 |



