해당 내용은 그래프 이론에서 출발한 것으로 처음 접하면 생각보다 내용이 복잡하고 프로그래밍과 깊은 연관이 있는 내용입니다. 설명이 난잡한 부분들이 많아서 이해가 가지 않는 부분이 있으시다면 추가적으로 공부하시는것도 좋지만, 모르더라도 라우팅 프로토콜의 동작방식을 이해하는데에는 무리가 없으니 무리하셔서 습득하실 필요는 없습니다.
1. 라우팅 알고리즘
동적 라우팅 프로토콜에서, 목적지까지 최적경로를 산출하여 라우팅 테이블을 유지, 관리하기 위해 사용되는 알고리즘을 라우팅 알고리즘이라고 합니다.
라우팅 정보를 취하는 범위에 따라 두가지로 분류 가능합니다.
분산 라우팅 알고리즘
- 이웃 노드와 정보를 교환하여 반복적이고 분산된 방식으로 수행.
- 거리 벡터 알고리즘 (Bellman-Ford)
글로벌 라우팅 알고리즘
- 네트워크 전체에 대한 완벽한 정보가 필요.
- 링크 상태 알고리즘 (Dijkstra)
2. 벨만포드 알고리즘 (Bellman-Ford Algorithm)
한 노드에서 다른 노드까지 최단거리를 구하기 위해 사용되는 알고리즘입니다.
다익스트라 알고리즘과는 다르게 가중치가 음수인 경우에도 사용이 가능하다는 장점을 지니지만 시간 복잡도가 크기 때문에 가중치가 양수인 경우에는 사용될 이유가 없습니다.
네트워크에서는 간선의 비용이 음수가 될 수 없으나 라우팅 테이블의 크기가 적고, 간단하기 때문에 소규모 네트워크에서 사용되는 거리 벡터 라우팅 프로토콜에 사용되는 알고리즘입니다.


우선 시작 노드를 결정하여 시작 노드는 0으로, 다른 노드는 무한대와 가까운 높은 값으로 초기화합니다.
이후 현재 노드에서 인접한 노드를 탐색하며 값을 비교하고, 비교값이 낮다면 갱신합니다.
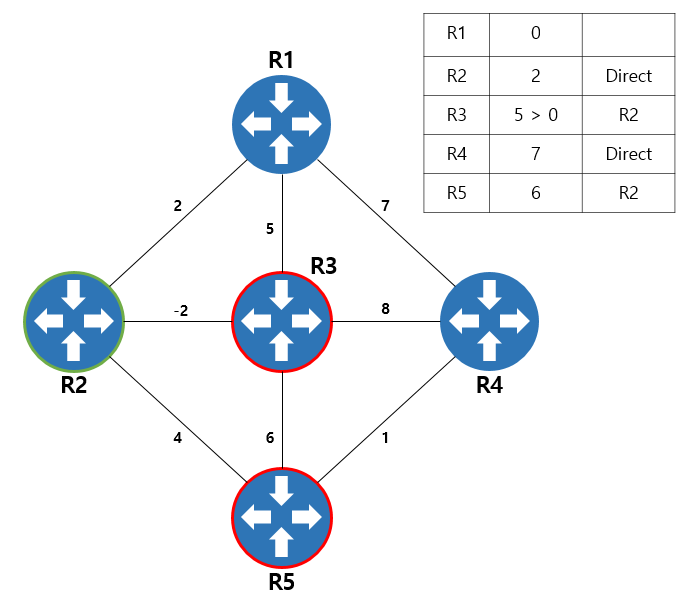

R1의 인접 노드를 모두 확인했으니, 링크가 연결된 다른 인접노드로 넘어가서 탐색을 시작합니다. 순서는 무관하지만 우선 R2로 넘어가보겠습니다. R3로 가는 경로의 값이 5 > 2+(-2) 이므로 최단경로를 갱신하고, R5로 향하는 경로값(2+4)을 갱신합니다. 다음으로는 R3로 넘어가서 인접노드를 탐색하고, 다음으로는 R4로 넘어가서 인접노드를 탐색하게 됩니다.
다음으로 시작 노드를 R2로 바꿔서 또 같은 과정을 반복하고, 인접 노드 탐색이 끝나면 다시 시작 노드를 R3로 바꿔가며 모든 노드의 탐색이 완료될 때 까지 이 과정을 반복합니다.
그래서 R1의 입장에서 네트워크를 바라보았을 때, R5 방향으로 가려면 R2를 거친다는 정보와 cost 가 6이라는 정보만 인지할 뿐, 네트워크의 구성이 어떻게 되어있는지는 파악할 수 없습니다.
이렇듯 각 노드는 이웃이 주는 정보들을 계산하고 이웃에게 계산 결과를 알린다는 점에서 분산적이고, 모든 과정이 완료되어 더이상 정보를 교환하지 않을 때까지 반복된다는 점에서 반복적이며, 모든 노드가 톱니바퀴처럼 동작할 필요가 없다는 점에서 비동기적인 특성을 지닙니다.
그런데 여기서 이상한 점을 하나 찾을 수 있습니다. 경로값이 음수인 R2, R3의 링크를 보겠습니다.

R2, R3의 경로값은 음수값인데, 이건 마치 어떤 톨게이트에서 고객 감사 행사로 100원을 받는 대신에 100원을 준다고 하는 것과 같습니다. 톨게이트에서 나오자마자 다시 돌아가서 반복적으로 이 돈을 받을 수 있다면 무한히 돌아서 창조경제가 가능해집니다.
이러한 사이클은 네트워크에서 치명적인 루핑이 발생하게 되고 최저 비용 거리를 구할 수 없게 됩니다. 최단 경로에서는 같은 노드를 두번 지날 일이 없기 때문에 거치는 노드의 수를 V라고 하면 (V-1)번 까지 반복하여 경로값을 확정했음에도 불구하고 최저비용이 갱신될 수 있을때 음수 사이클이 있다고 판단할 수 있게 됩니다.
네트워크에서는 루핑 문제를 방지하기 위해 RIP와 같은 프로토콜에서는 Maximum Hop Count를 15로 설정하기 때문에 네트워크의 규모가 크다면 사용할 수 없습니다. 또한 30초마다 주기적인 갱신을 위해 이 과정들을 반복하며 브로드캐스팅하기 때문에 네트워크에 부하가 발생합니다.
외에도 경로 이상 상태가 발생했을시 180초간 대기하므로 Down Time이 길고, 회선 상태를 무시하고 홉 수만을 계산하므로 비효율적인 라우팅이 이뤄질 수 있다는 단점들이 있습니다.
3. 다익스트라 알고리즘 (Dijkstra Alogorithm)
다익스트라 알고리즘은 음의 가중치가 없는 그래프를 가정하고, 모든 노드까지의 최단거리를 구하는 알고리즘입니다. 인공위성 GPS 소프트웨어 등에서 자주 사용되는만큼 라우팅 프로토콜에서도 아주 중요합니다.
다익스트라 알고리즘에서 최단 거리는 여러 개의 최단 거리로 구성됩니다. 하나의 최단 거리를 구할 때, 이전까지 구했던 최단 거리 정보를 그대로 사용한다는 특징을 가집니다. 이러한 점에서 벨만포드 알고리즘과 동작방식에 차이가 있는데, 다음 예시로 확인해보겠습니다.


R1을 출발지로 가정하겠습니다. 다른 모든 노드의 경로값은 무한대로 초기화하고, 인접노드의 경로값을 갱신합니다. 이후에 R2의 경로값이 가장 낮으므로 우선 방문합니다.


R2를 방문하고 인접노드의 경로값을 계산합니다. R5, R6로 가는 경로값을 갱신하고, 방문하지 않은 노드중 가중치가 가장 적은 노드는 R3이므로 R3를 방문하고 가중치를 비교합니다. 이경우 기존의 경로값보다 작은 경로값이 없기에 갱신되지 않습니다.

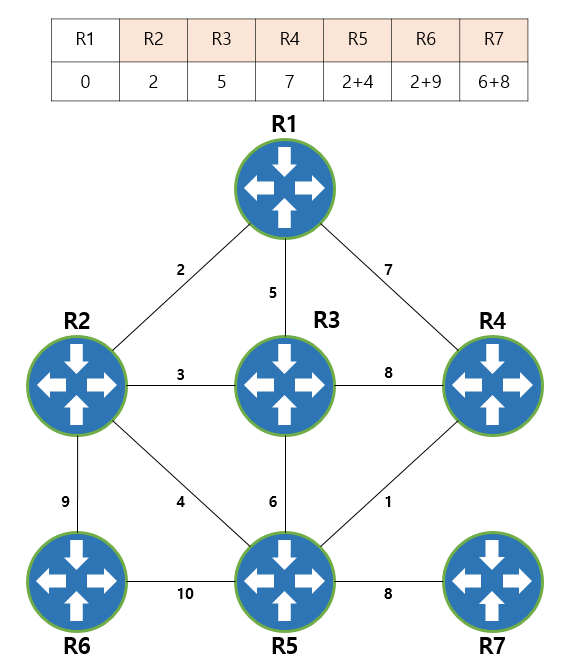
다음으로 가중치가 적은 R5를 방문하고, R7의 경로값을 갱신합니다. 이후 같은 과정을 반복하며 테이블에서 가중치가 적은 노드들을 차례로 모두 방문하게 되면 갱신이 끝나게 됩니다.
여기서 만약 목적지가 R7이라고 가정한다면 우선 R7과 연결된 R5로 가야하고, R5로 가는 경로는 가중치를 기반으로 R2를 경유해야 한다는것을 파악할 수 있습니다. R1의 입장에서 모든 노드를 방문하였으니 전체 구성이 어떻게 되어있는지를 파악할 수 있게 되며 최단경로의 조합으로 목적지를 찾을 수 있게 됩니다.
4. 가중치가 음수일 때 차이점
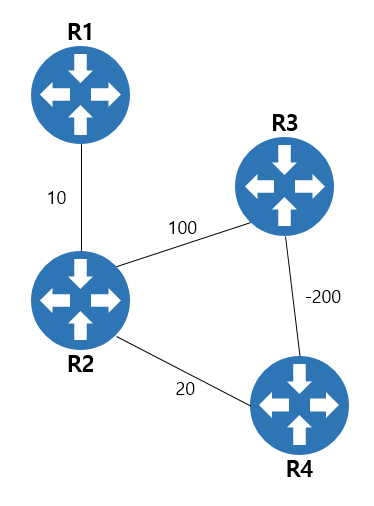
위 예시에서, 출발지가 R1이고 목적지가 R4라고 가정한다면 R3를 경유하는것이 더 좋습니다. 다만 다익스트라 알고리즘은 기본적으로 탐욕 알고리즘(Greedy Algorithm) 방식1이므로, R3를 경유하여 비용이 감소하는 경우를 고려하지 못합니다.

다익스트라 알고리즘은 R2에서 R3로 갈지, R4로 갈지 판단할 때 음수가 없다고 가정하면 다익스트라 알고리즘의 Greedy 한 탐색방식이 좋은 결과를 가져올 수 있으나 음수가 있을 경우에는 되려 손해를 보게 됩니다.
반면 벨만포드 알고리즘의 경우에는 R3가 R2에게 가중치가 -200이라는 것을 알려줄 수 있기 때문에 자신을 경유하는 경로를 알려줄 수 있겠죠.
물론 네트워크에서 회선비용이 음수가 될 일은 없으니, 각 알고리즘의 동작방식에 이러한 차이점이 있다는 점만 기억하시면 됩니다.
- 탐욕 알고리즘 - 선택의 순간마다 최적의 상황만을 쫓아 최종적인 해답에 도달하는 방법. [본문으로]
'네트워크, 보안' 카테고리의 다른 글
| 라우팅 - RIPv2 인증 (Authentication) (0) | 2022.04.05 |
|---|---|
| 라우팅 - RIP (Routing Information Protocol) (0) | 2022.03.29 |
| 라우팅 - 라우팅 개요 (0) | 2022.03.03 |
| 라우팅 - Inter-VLAN Routing (0) | 2022.02.17 |
| 라우팅 - 정적 라우팅 (Static Routing) (2) | 2022.02.03 |



